
IT之家2月14日音讯,字节越过通告,今天,豆包大模子慎重干与2.0阶段。豆包2.0(Doubao-Seed-2.0)围绕大范畴出产环境下的使用需求作念了系统性优化,依托高效推理、多模态领略与复杂指示践诺才略,更好地完成真正宇宙复杂任务。
IT之家注释到,豆包2.0系列包含Pro、Lite、Mini三款通用Agent模子和Code模子,生动适配种种业务场景:
豆包2.0Pro面向深度推理与长链路任务践诺场景,全濒临标GPT5.2与Gemini3Pro;
2.0Lite兼顾性能与本钱,空洞才略超越上一代主力模子豆包1.8;
2.0Mini面向低时延、高并发与本钱明锐场景;
Code版(Doubao-Seed-2.0-Code)专为编程场景打造,与TRAE皆集使用适度更佳。
现在,豆包2.0Pro已在豆包App、电脑端和网页版上线,用户聘用「巨匠」形式即可对话体验;豆包2.0Code接入了AI编程居品TRAE;面向企业和竖立者,火山引擎也已上线豆包2.0系列模子API劳动。
多模态领略才略全面升级,多数基准达SOTA水平
豆包2.0全面升级了多模态才略,在种种视觉领略任务上均达到宇宙顶尖水平,视觉推理、感知才略、空间推理与长高下文领略才略进展尤为凸起,豆包2.0Pro在大多数相干基准测试中取得最高分。
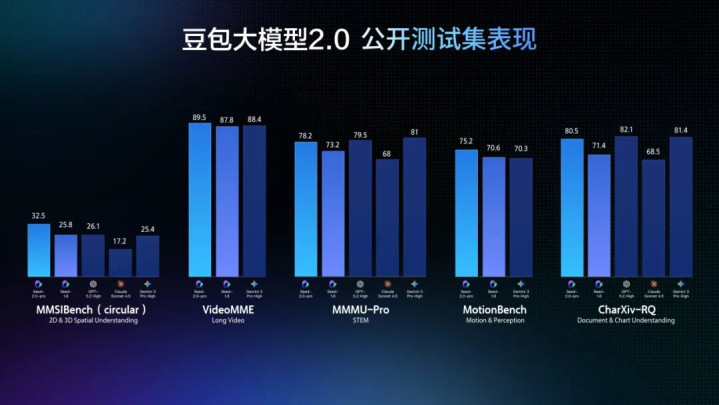
濒临动态场景,豆包2.0强化了对工夫序列与畅通感知的领略才略,在TVBench等重要测评中处于当先位置,且在EgoTempo基准上杰出了东谈主类分数,标明它对“变化、动作、节律”这类信息的捕捉更为巩固,在工程侧可用性更高。
长视频场景中,豆包2.0在大多评测上超越了其他顶尖模子,且在多个流式及时问答视频基准测试中进展优异,能行为AI助手完成及时视频流分析、环境感知、主动纠错与情谊追随,杀青从被迫问答到主动率领的交互升级,可诈欺于健身、穿搭等追随场景。
LLM与Agent进展大幅强化,亚搏app官网长程任务践诺才略晋升
{jz:field.toptypename/}晋升长程任务践诺才略,需要丰富的真正宇宙常识。通过加强长尾规模常识,豆包2.0Pro在SuperGPQA上分数杰出GPT5.2,并在HealthBench上拿到第又名,在科学规模的全体获利与Gemini3Pro和GPT5.2稀奇。
在推理和Agent才略评测中,豆包2.0Pro在IMO、CMO数学奥赛和ICPC编程竞赛中赢得金牌获利,也超越了Gemini3Pro在PutnamBench上的进展,展现了矫健的数学和推理才略。在HLE-text(东谈主类的临了试验)上,豆包2.0Pro取得最高分54.2分,在器具调用和指示撤职测试中也有出色进展。
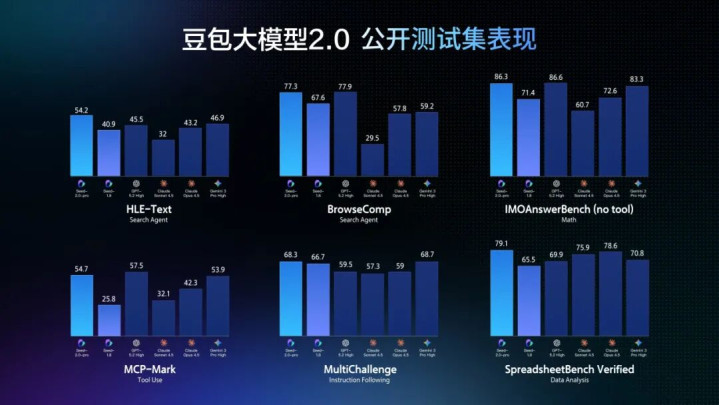
豆包2.0还进一步镌汰了推理本钱。其模子适度与业界顶尖大模子稀奇,但token订价镌汰了约一个数目级。在试验宇宙的复杂任务中,由于大范畴推理与长链路生成将花费广泛token,这一册钱上风将变得更为重要。
Code模子晋升竖立服从,快速搭建复杂诈欺
豆包2.0Code是基于2.0基座模子,针对编程场景进行优化的版块。其强化了代码库解读才略,还晋升了诈欺生成才略。此外,豆包2.0Code还增强了模子在Agent责任流中的纠错才略。
该模子已上线TRAE中国版行为内置模子,维持图片领略和推理。
以竖立一个「TRAE春节小镇·马年庙会」互动名堂为例。这是一个比拟复杂的场景,然而通过TRAE+豆包2.0Code,只需要1轮提醒词,就能构建出基本的架构和场景,再历程几次调试,整个5轮提醒词,就可完成这个作品。
字节越过官方称,豆包大模子2.0系列的更新,是面向试验宇宙复杂任务的新着手。将来,团队将不竭面向真正场景迭代模子,束缚探索智能上限。
 备案号:
备案号: